You’ve bought code generation tools. Your developers are shipping faster than ever.
But here’s what nobody warned you about: the PR queue is a parking lot now. Senior engineers are drowning in diffs they don’t have time to read properly. “Looks Good To Me” (LGTM) is the new code review standard. And security issues? They ship on Friday afternoons just like they always did.
The code generation layer accelerated. The review layer stood still. That is the gap AI code review fills, and why it has gone from nice-to-have to infrastructure.
Why the old system broke
Pull request review used to be a manageable ritual. Teams were small, PRs were contained, and a senior engineer could open the diff, read the context, ask questions, and enforce standards.
Three things broke that equilibrium.
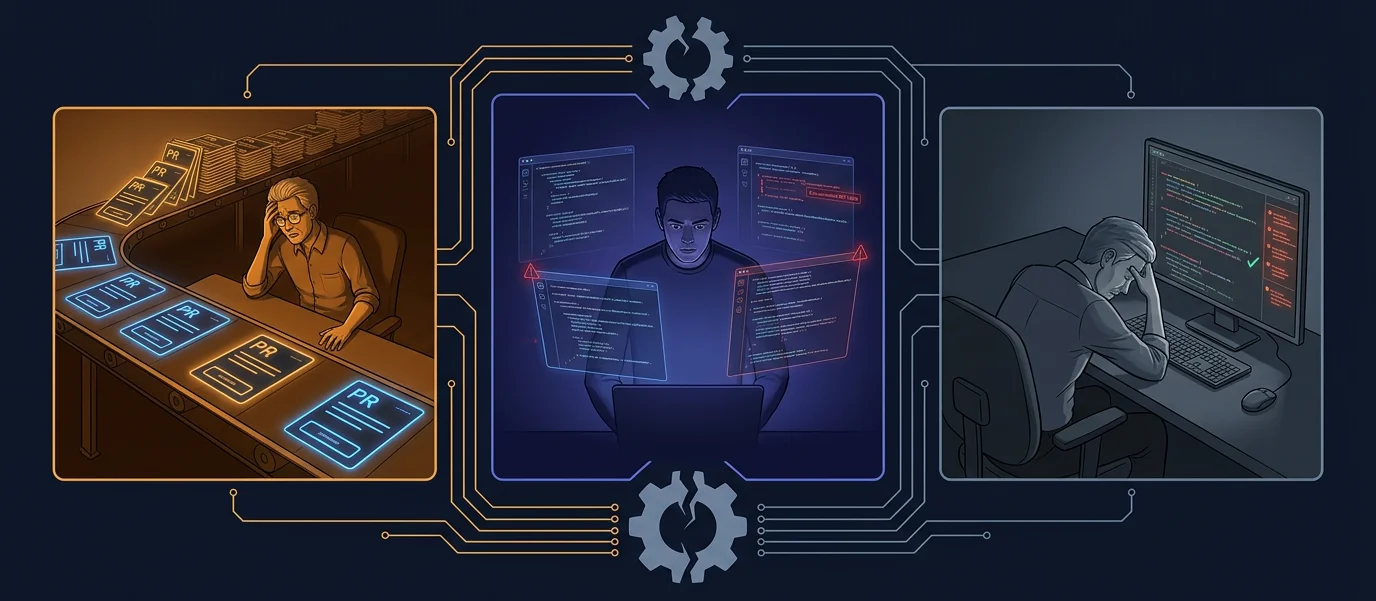 The three structural failures that broke manual review: velocity, generated code trust, and human scaling limits
The three structural failures that broke manual review: velocity, generated code trust, and human scaling limits
PR velocity outpaced reviewer capacity. AI-assisted development increased code generation speed by three to five times. PRs that used to take a day now open in hours. But the number of senior engineers stayed flat. Review queues grow, feedback latency stretches, and “LGTM” becomes the default.
AI-generated code needs more scrutiny, not less. With Vibe Coding, developers are no longer authors of every line. They are reviewers of machine-generated output, code they did not write, in patterns they may not fully understand. The assumption that generated code is correct is dangerous. Hallucinated APIs, missing error handling, and subtle security gaps slip through because the developer trusts the tool that wrote it.
Human review does not scale. After the fifth PR of the day, attention fragments. Complex diffs get skimmed. Security patterns are missed. Architectural violations are rubber-stamped. Consistency collapses under volume. The tenth review is never as thorough as the first.
The pipeline is out of balance. Code generation accelerated. Code review stood still.
What a real AI code review tool actually does
AI code review extends the reach of senior engineers rather than replacing them. A well-designed system adds things human review alone cannot deliver at scale.
An AI reviewer does not get tired. It applies the same standard to the first PR and the five hundredth. It does not have a bad day, miss a meeting, or rush to lunch.
Humans are excellent at architecture and business logic. They are poor at spotting every instance of a SQL injection vulnerability across a large diff, or identifying that a function introduced an N+1 query, or noticing that error handling was added in three places but missed in a fourth. AI review catches what humans consistently miss.
Every human reviewer has preferences, blind spots, and varying expertise. One reviewer catches security but misses performance. Another catches style but misses architecture. An AI tool applies the same taxonomy to every PR, every time.
The most expensive part of review is the waiting. A PR sits in queue for hours or days before a human touches it. An AI reviewer surfaces findings in minutes, so developers can act while the context is still fresh.
What to look for (and what to avoid)
Not all AI code review tools are built for the same purpose. Here is what separates the ones that improve quality from the ones that generate noise.
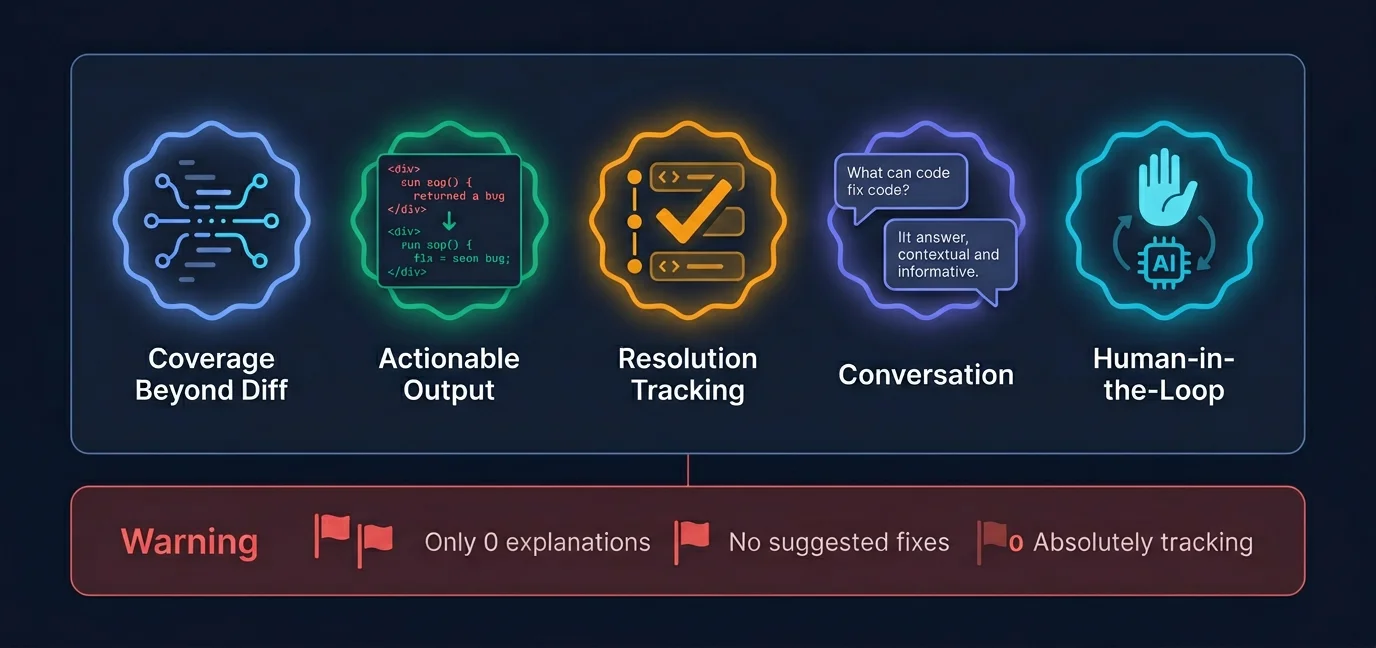 What separates useful AI review tools from noisy ones: coverage, actionability, tracking, conversation, and human governance
What separates useful AI review tools from noisy ones: coverage, actionability, tracking, conversation, and human governance
Coverage beyond the diff
The best tools review more than the changed lines. They analyse the function, the class, the imports, and the call graph. A diff-only reviewer will miss that your new function calls an old one that lacks error handling. A context-aware reviewer catches it.
Actionable output, not just flags
The difference between a useful tool and a noisy one is what it delivers. Look for three things on every issue:
- What the problem is. A plain-language description, not a rule ID.
- What happens if left unfixed. The concrete consequence: data loss, outage, security breach.
- A ready-to-apply fix. Actual replacement code, not a suggestion to “consider refactoring.”
If the tool only flags issues without explaining why they matter or how to fix them, it becomes another source of developer fatigue.
Resolution tracking
A critical feature most teams overlook: does the tool remember what it already flagged? When a developer pushes a fix, does the tool recognise it and resolve the issue automatically? Or does it post the same comment again on the next push, creating noise and training developers to ignore it?
Incremental re-review is what makes an AI review tool sustainable at scale. Analyse only what changed, carry forward open issues, auto-resolve fixed ones.
Conversation capability
Developers will disagree with findings. They will want to understand the risk better. They will need an alternative fix that does not require a full refactor. The best tools allow developers to reply directly to an issue and receive a context-aware answer grounded in the exact code, not a generic docs link.
Human-in-the-loop governance
This is the most important design principle, and the one most tools get wrong.
AI should surface issues for human decision. It should not auto-fix and push.
When a tool automatically rewrites code and commits it, two things happen. First, the developer never learns why the original code was problematic. They do not understand the vulnerability, the performance anti-pattern, or the architectural violation. They just see that the tool “fixed it.” Over time, this erodes engineering capability. The team becomes dependent on the tool and less capable of writing quality code independently.
Second, auto-fixes bypass the review and approval process that exists for a reason. A human should read the finding, understand the impact, evaluate the suggested fix, and decide whether to apply it. This is not bureaucracy. It is how engineers build judgment.
The right design is human-in-the-loop. The AI observes, analyses, surfaces structured findings with description, impact, and suggested fix, and the human decides. The tool makes the developer smarter. It does not make them dumber by removing the thinking.
AI code review vs. SAST and linters
Most teams already have security scanning and linting. They ask a fair question: why another tool?
| Tool type | What it actually does |
|---|---|
| SAST | Rule-based, periodic security scans. Catches known vulnerability signatures and CVE patterns. Does not understand architecture, business logic, or performance. Runs on schedule, not on every commit. |
| Linters | Fast, local, shallow. Enforces formatting and naming. Ensures code looks consistent. Does not evaluate security, performance, or architectural soundness. |
| AI review | Semantic understanding of code at the design level. Finds architectural violations, performance anti-patterns, and logic errors no rule set can codify. Runs continuously on every commit. Delivers fixes, not just alerts. |
SAST finds known bad patterns. AI review finds unknown bad design. Linters enforce style. AI review enforces quality. Teams need all three, but they serve different layers of the pipeline. Confusing a linter with an AI review tool is like confusing a spell-checker with an editor.
The threat landscape is accelerating
Here is something that does not get talked about enough. The threats themselves are evolving faster than rule sets can be updated.
AI is being used for exploitation as aggressively as for defence. Attackers use large language models to generate novel vulnerability patterns, obfuscate malicious code, and discover zero-day variants. The attack surface is no longer static. It is generated.
Traditional SAST relies on signature-based detection. A new vulnerability requires a new rule. A new rule requires a vendor update. That cycle takes weeks or months. In that time, attackers have moved to the next variant.
AI code review tools that use semantic understanding can recognise suspicious patterns even when the specific signature is new. They evaluate what the code does, not just whether it matches a known blacklist. A function that constructs dynamic SQL in an unusual way, an authentication bypass that does not match any existing CWE, a data flow that leaks PII through an unexpected channel. Semantic analysis catches these. Signature-based tools miss them.
Static defences cannot keep up. The only approach that scales understands code by what it does, not by what it matches.
But my AI coding agent already reviews code
This is the most common objection we hear. All coding agents review what they generate. Why a separate tool?
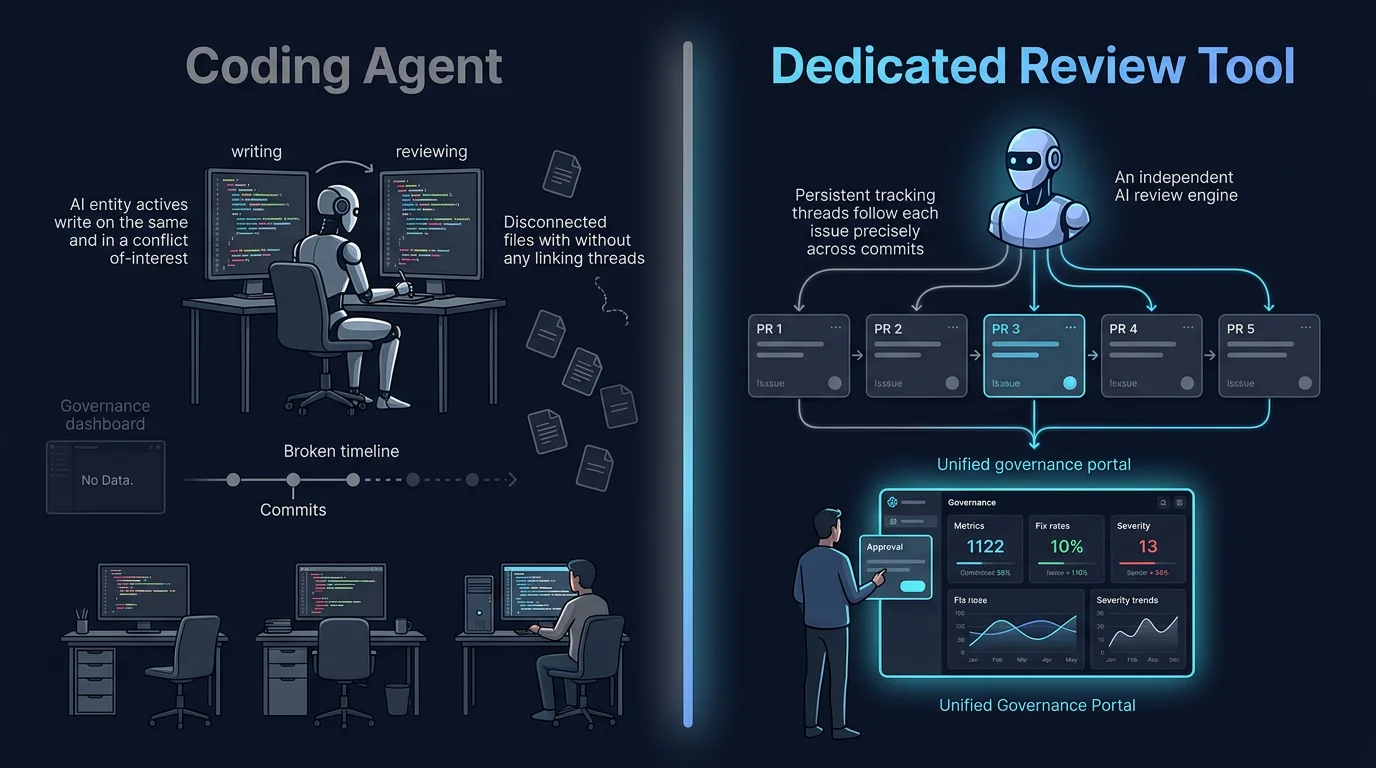 A coding agent reviewing its own code creates a conflict of interest. A dedicated review tool brings independence, tracking, and governance.
A coding agent reviewing its own code creates a conflict of interest. A dedicated review tool brings independence, tracking, and governance.
Coding agents optimise for generation speed, not review rigour. Their job is to produce working code quickly. Review is a secondary concern, often performed by the same model that wrote the code. A model reviewing its own output has a conflict of interest. It justifies its choices rather than catching its mistakes.
Coding agents do not track resolution across commits. They review the current state of the file. They do not maintain a persistent database of what was flagged, what was fixed, and what remains open. If a developer pushes three commits to a PR, the agent starts from scratch each time. It cannot tell that commit two fixed an issue from commit one.
Coding agents do not enforce team-wide standards consistently. Each developer uses their own agent, with their own prompts, model, and settings. One gets thorough security review. Another gets none. Standards become a function of individual tool configuration, not organisational policy.
Coding agents do not feed a governance layer. Engineering leaders need visibility: fix rates, severity trends, category breakdowns, PR timelines across all repositories. A coding agent runs in a developer’s IDE. It does not aggregate findings into a portal. It does not block merges when critical issues remain open. It does not produce audit trails.
A dedicated AI code review tool adds independence from the generation layer, persistent tracking, consistent standards, and governance visibility. The coding agent writes the code. The review agent validates it. The portal tracks it.
You would not let the author be the only proofreader of a book. The same principle applies here.
How we built PASSR
We built PASSR because we saw the same pattern at every engineering team we consulted. Review queues backing up. The same security and performance issues recurring. Senior engineers burning out on boilerplate while architecture review was deferred.
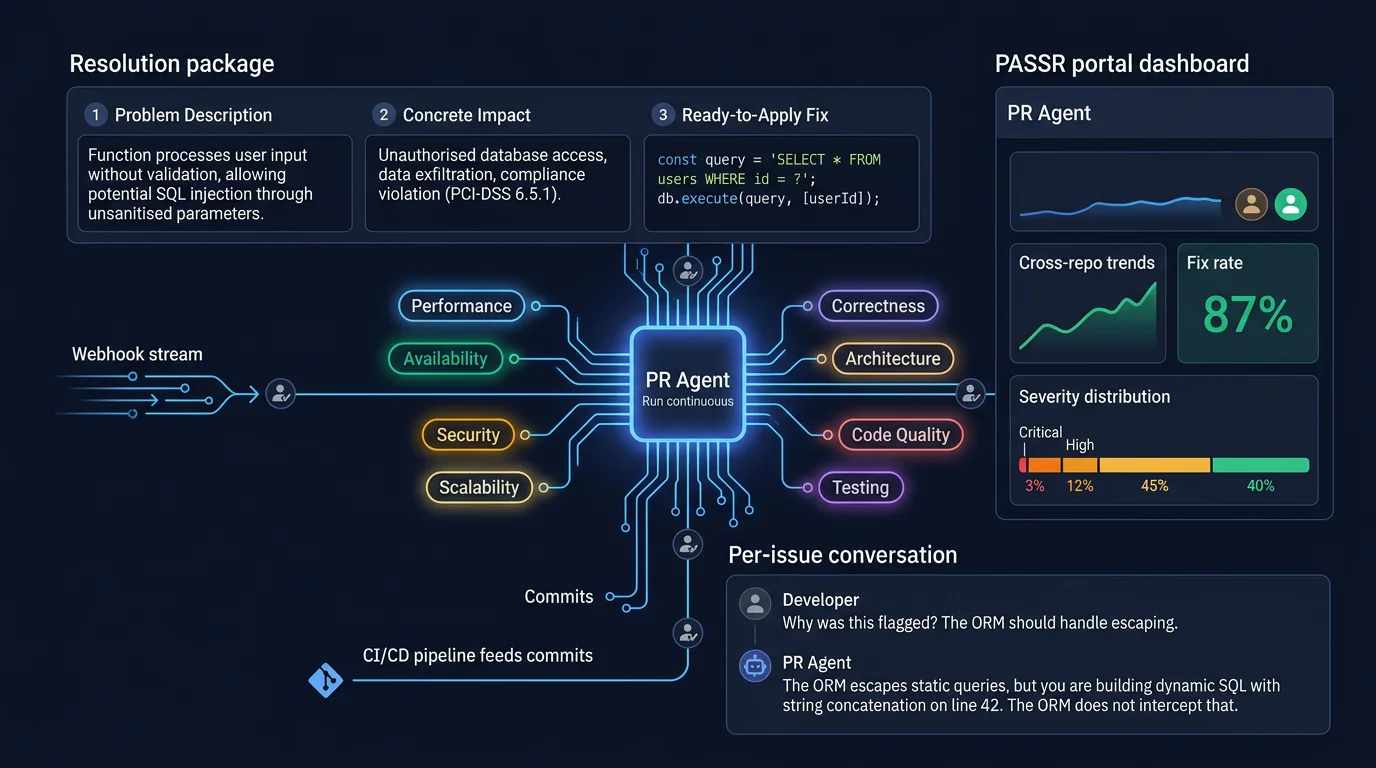 PASSR runs as a background agent: webhooks, eight dimensions, resolution packages, governance portal, and per-issue conversation - with humans in control
PASSR runs as a background agent: webhooks, eight dimensions, resolution packages, governance portal, and per-issue conversation - with humans in control
We built a background agent, not a chat interface. PR Agent runs silently via webhooks and CI/CD hooks. It does not wait to be asked. It reviews every pull request and every commit the moment code lands. Developers do not change their workflow. The feedback arrives in the same PR thread they already check.
We designed the output as a resolution package, not a comment. Every issue includes a plain-language description of the problem, the concrete impact if left unfixed, and a ready-to-apply code fix. Developers read, understand, and apply. They do not spend twenty minutes interpreting a vague flag and searching for what to do.
We track everything in a portal. Findings flow into the PASSR portal where teams see cross-repo trends, fix rates, severity distributions, and PR timelines. Engineering leaders manage quality as a metric, not an assumption.
We review every commit, not just every PR. Most review tools only trigger on PR open events. They miss the commits that land on a branch before the PR is created. PR Agent reviews standalone commits too, so issues are caught before they ever enter the PR.
We apply the PASSR framework across eight dimensions. Performance, Availability, Security, Scalability, plus correctness, architecture, code quality, and testing. Security issues are CWE-mapped. Performance issues trace to specific anti-patterns. Architecture violations reference design principles. Every finding is categorised, severity-scored, and tracked.
We enable per-issue conversation. Developers reply directly to any issue to ask why it was flagged, request an alternative fix, or challenge the finding. PR Agent answers in context, scoped to the exact file and function. Not a docs link. A real explanation.
What you get
- Minutes to first feedback instead of hours or days in queue
- One-click inline suggestions on git providers
- Incremental re-review: fixed issues auto-resolve, new ones surface, unchanged issues carry forward
- Per-issue conversation: ask why, explore alternatives, understand root causes without waiting for a senior reviewer
- PR descriptions and labels generated automatically the moment a PR opens
- Merge protection when critical issues remain open
- PASSR portal: cross-repo visibility, fix rates, severity trends, category breakdowns, PR timelines
- Bring your own LLM: OpenAI, Anthropic, Groq, or self-hosted via LLMProxy
Working with Flytebit
At FLYTEBIT TECHNOLOGIES, we build agentic AI systems that run in the background so your team can focus on what matters. See how agentic AI systems work across the full development pipeline.
If you need AI software development services that cover the full pipeline - from strategy to deployed agents - start with a conversation.
PASSR is our engineering intelligence platform for continuous code review and quality governance. If your team is drowning in PR queues, we can help you understand exactly where the bottlenecks are and what to do about them.
Not sure where your organisation stands today? The Vibe Coding Transformation Readiness Quick Check takes five minutes and gives you a per-function view of where your pipeline is most exposed.
Related reading
Why the next two to three years will separate the teams that automated their full pipeline from the teams that only automated one link in it.
The five core components of agentic systems and what makes them different from the AI tools you are already using.
Key takeaways
- ✅ Manual review broke because PR velocity outpaced human capacity. AI-assisted development generates 3–5x more code. Reviewers did not scale with it.
- ✅ The best tools deliver resolution packages, not flags. Description, impact, and ready-to-apply fix on every issue.
- ✅ Human-in-the-loop is non-negotiable. AI surfaces findings. Humans decide. Auto-fixes erode engineering capability.
- ✅ SAST and linters are complementary, not substitutes. SAST finds known patterns. AI review finds design-level issues. Linters enforce style.
- ✅ Coding agents do not replace dedicated review tools. They lack tracking, consistency, governance, and independence from the generation layer.
- ✅ The threat landscape is accelerating. Signature-based defences cannot keep pace with AI-generated attacks. Semantic analysis is the only scalable response.

Ready to Transform Your Business with AI?
Let's discuss how Agentic AI and intelligent automation can help you achieve your goals.